
Spring Data JPA는
SQL 중심 개발이 아닌 객체 중심 개발을 위한
자바 ORM(Object-Relational Mapping) 표준 기술입니다.
따라서 테이블을 직접 DB에 먼저 생성하는 방식이 아니라,Spring Boot에서 Entity 객체를 구성하면 JPA에 의해 테이블이 생성됩니다.Entity를 기반으로 DB 설계를 하다 보면Entity 객체에서 id 값의 타입에 대한 고민을 하게 됩니다.
프로젝트 시id 값의 타입을 선택할 때,int, long, Long 그리고 UUID 중 어떤 타입을 선택하는 게 적절할까에 대한 고민을 했습니다.
🚀 Int vs long vs Long
데이터의 크기와 데이터의 타입 그리고 디스크 용량의 상관관계는DB 성능 문제를 일으킬 수 있습니다.
예를 들어 테이블에 데이터를 넣을 때,
- 크기가 큰 데이터에 대해 작은 데이터 타입을 선택하거나
- 데이터는 작은데 데이터의 유형을 크게 선택하면
두 경우 모두 성능 문제가 발생합니다.
성능 문제는 곧 비용 문제랑 직결되므로
올바른 데이터 타입을 선택하는 것은 중요합니다.
Spring Boot에서 JPA를 사용할 때 Entity설계 시 id 값은DB에서 테이블에 있는 행들의 주 식별자 = PK(Primary Key) 역할입니다.
DB에서 테이블의 행 식별을 위해선 행마다 중복되지 않는 id 값들이 필요합니다.
데이터 삽입 시 중복되지 않는 값을 계속 부여하기 위해서
랜덤한 문자열을 생성하는 방식보단
중복 방지에 더 유리한 랜덤하거나 규칙적인 숫자 생성이 고려됩니다.
그래서 MySQL의 AUTO_INCREMENT를 활용해
id값이 자동으로 1씩 증가되는 규칙적이고 보편적인 방식을 생각할 수 있습니다.
Spring Boot에선 이 규칙적인 값을 담을 id 값의 타입에 대해 생각해야 합니다.id 값은 1씩 증가되는 정수이므로 int, long, Long 타입이 적절합니다.
그렇다면 이 세 타입은 각각 어떤 차이가 있을까요?
먼저 원시 타입과 참조 타입으로 나뉩니다.
⭐ 원시 타입(Primitive Type)
- 원시 타입은 정수, 실수, 문자, 논리 리터럴 등 실제 메모리에 데이터 값을 직접 저장하는 타입입니다.
- 직접 Null을 할당할 수 없습니다.
- Null 할당을 위해서는 래퍼 클래스(Wrapper Class)가 사용됩니다.
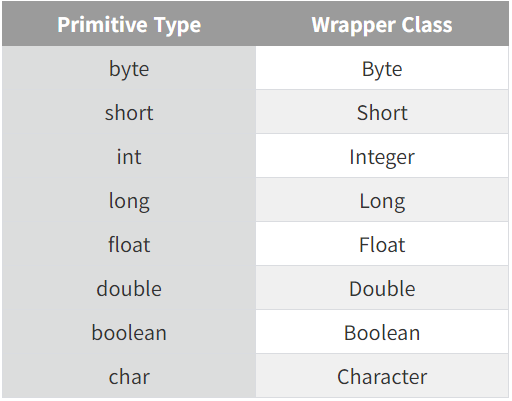
래퍼 클래스는 클래스이기 때문에 참조 타입입니다. - 메모리의
Stack에 실제 값이 할당됩니다. 실제 값 접근 시Stack만 접근합니다. byte, short, int, long, float, double, boolean, char가 있습니다.
⭐ 참조 타입(Reference Type)
- 참조 타입은 객체의 주소를 저장하는 타입으로 메모리 주소 값을 통해 객체를 참조하는 타입입니다.
- 객체이기 때문에 Null 할당이 가능합니다.
- 컴파일 시 주소 값은
Stack에, 런타임 시Heap에 실제 값이 할당됩니다. 따라서 실제 값 접근 시Stack에서Heap으로 최소 두 번 접근합니다. - 일부 타입에 대해 언박싱 과정(ex. Integer -> int, Long -> long)을 거쳐야 합니다.
원시 타입을 제외한 문자열, 배열, enum, 클래스, 인터페이스가 있습니다.
여기서 int와 long은 원시 타입이고,long의 래퍼 클래스인 Long은 참조 타입입니다.
각 타입이 실제 메모리에서 차지하는 크기는int는 Stack에서 4byte,long은 Stack에서 8byte,Long은 Stack에서 8byte(주소 값), Heap에서의 실제 메모리 사용량은 객체의 크기와 JVM 구현에 따라 달라집니다.
메모리 측면에선
한 번만 접근하는 원시 타입 int, long의 성능이
두 번 이상 접근하는 참조 타입 Long보다 좋습니다.
저장 범위 측면에선int의 범위는 -2,147,483,648 ~ 2,147,483,647이고,long의 범위는 -9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807입니다.
결국 수 십억 개의 데이터를 가지지 않을 것이라면 메모리 용량, 서버 저장 공간, 쿼리 속도 측면에서 int가 중규모 서버 운영에 훨씬 효율적이고, 데이터가 많이 누적될 것을 고려하면 long이 유리합니다.
그런데 AUTO_INCREMENT를 사용하면 id 값은 런타임 시 동적 할당됩니다.id 값은 정적 데이터(ex. 더미 데이터)가 없으면 컴파일 시 Null일 수도 있습니다.
따라서 런타임 이후 생성 시점에서 값이 결정되므로 Long이 사용되어야 합니다. 참고로 long과 Long은 MySQL에서 BigInt입니다.
🚀 UUID(Universally Unique Identifier)
앞서 소개한 AUTO_INCREMENT를 요약하자면
- 간편성:
AUTO_INCREMENT를 사용하면 개발자가 고유한id를 직접 관리하지 않아도 됩니다. 이는 코드를 단순화하고 실수를 줄여줍니다. - 고유성 보장:
AUTO_INCREMENT는 항상 고유한 값을 생성하므로, 데이터의 일관성을 유지하는 데 도움이 됩니다. - 성능 최적화:
AUTO_INCREMENT필드는 인덱스로 사용되는 경우가 많아, 검색 성능을 향상시키는 데 도움이 됩니다. BigInt을 사용하기 때문에 용량도 유리합니다.
하지만 단점도 존재합니다.
CUD성능 저하:AUTO_INCREMENT필드는 새로운 행이 삽입될 때마다 업데이트되어야 합니다. 이로 인해CUD작업이 느려질 수 있습니다.- 값의 낭비: 삭제된 행의
AUTO_INCREMENT값은 재사용되지 않습니다. 따라서, 자주 행이 추가되고 삭제되는 경우,AUTO_INCREMENT값이 빠르게 소진될 수 있습니다. - 데이터 복제 문제: 여러 서버에 데이터를 복제하는 경우, 각 서버에서 생성된
AUTO_INCREMENT값이 충돌할 수 있습니다. - 데이터 이동의 어려움:
AUTO_INCREMENT필드를 가진 테이블의 데이터를 다른 테이블로 이동하거나 복사할 때,AUTO_INCREMENT값이 변경될 가능성이 있습니다. AUTO_INCREMENT는 순차적으로 증가하기 때문에, 데이터의 생성 패턴이 노출될 수 있습니다.
회원 테이블같이 보안이 중요한 데이터들은 AUTO_INCREMENT를 사용하는 것보다 다른 전략이 고려됩니다. 그 중 UUID를 생각할 수 있습니다.
UUID의 사용 이유는 다음과 같습니다.
- 분산 시스템 호환성:
UUID는 충돌 확률이 약 10억분의 1로, 여러 데이터베이스 서버 간에 데이터를 복제하거나 분산 시스템을 구축할 때 유용합니다.AUTO_INCREMENT를 사용하는 경우id충돌이 발생할 수 있지만,UUID는 이러한 문제를 방지합니다. - 비순차적인
id생성:UUID는 비순차적으로 생성되므로, 데이터의 생성 패턴을 숨길 수 있습니다. - 오프라인 생성 가능:
UUID는DB연결 없이 클라이언트(Spring Boot) 측에서 생성할 수 있습니다. 이는 네트워크 지연을 줄이고, 애플리케이션의 성능을 향상시킬 수 있습니다.
그러나 UUID의 큰 단점은 16byte라는 점입니다.BigInt보다 크기 때문에AUTO_INCREMENT에 비해 인덱스 성능이 뒤쳐지고, 저장 공간을 더 차지합니다.
그러므로 보안이 성능보다 중요한 다음과 같은 상황에서 사용해야 합니다.
- 클라이언트에서
PK값이 보이는 경우 ex) URL 쿼리 값 - 클라이언트에서 식별자 역할을 해야 할 경우 ex) 쿠폰의 코드 값
🚀 결론
좋은 순으로 비교한다면
- 속도:
int>long>Long>UUID - 용량(범위):
long=Long>int>UUID - 저장 공간:
int>long>UUID>Long - 보안:
UUID>int=long=Long
로 나타낼 수 있고,
int- 데이터의 수가 적으면 유리하다.long- 데이터의 수가 많고, Not Null이 보장되면 유리하다.Long- 데이터의 수가 많고, Nullable이면 유리하다.UUID- 회원 테이블같이 보안과 안정성이 성능보다 더 요구되면 유리하다.
정도로 정리 할 수 있습니다.
결론은 상황에 따라 성능, 보안, 안정성을 고려해 AUTO_INCREMENT를 사용할 지 UUID를 사용할 지 신중히 선택해야 합니다.