테스트 계획 수립 ➡ 시나리오 짜기 ➡ 테스트 진행 ➡ 결과 분석 ➡ 적용 과정을 거친다고 한다.
성능 개선을 위한 테스트 과정을 좀 더 파다보니
생각보다 준비할 것도 많고 고려할 점도 많은 것 같고
이런 부분에 대한 러닝 커브가 걱정돼서 할까 말까 고민하다가 잠 못 이루고 그랬는데
어쨌든 조회할 테이블에 데이터가 누적될수록 당연히 조회 성능은 떨어지기 마련이고
이런 대용량 데이터를 다루는 부분에서 내 쿼리문은 솔직히 많이 형편없다고 생각하는 상황이어서
검색 로직이든 쿼리문이든 개선할 유의미한 동기가 필요했기에 힘을 내서 손을 댔다.
그리고 이것 말고도 할 게 너무 많아서
주어진 시간이 얼마 없다는 마인드로 머리 오지게 박으면서 테스트를 진행했다.
이번 부하 테스트를 진행하면서 내가 겪은 고충이나 공부한 내용들을 최대한 기록하겠다.
참고로 나도 다양한 API를 테스트하고 싶은데
우선 이번 글에선 한 개의 로그인이 필요없는 API만 테스트를 할 것이다.
이유는
1. 현재 플젝에는 ID/PW 로그인이 없고 OAuth 로그인만 사용하고 있다. 그런데 플젝에서 OAuth 로그인 과정이 생각보다 복잡하기 때문에 Mock으로 토큰을 만들어 주는 과정이 들어가면 스크립트 구현 난이도가 많이 올라간다.
2. 따라서 로그인이 필요없는 API들을 우선 테스트할 예정이다.
3. 이 문제점을 많이 고민해 봤는데 결론은 모든 테스트가 개발 서버에서 진행되기 때문에 추후에 로그인이 필요한 API들은 잠시 권한 허용(토큰이 필요없게)을 해놓고 할 것 같다.
본격적으로 준비를 해보자.
🚀 사전 준비
⭐ 디스크 전체 용량 확인
먼저 당연하게도 테스트 대상인 테이블에 대용량 데이터를 미리 넣어놔야 한다.
넣어야 할 데이터의 크기가 디스크 전체 용량을 넘치면 안 되므로
넣기 전에 우선 디스크에서 내가 사용하고 있는 용량을 알아야 한다.
SELECT ROUND(SUM(data_free)/1024/1024,3) "total_size(MB)",
ROUND(SUM(data_length+index_length)/1024/1024,3) "used_size(MB)"
FROM information_schema.tables;
이 쿼리문을 실행하면 현재 사용중인 디스크의 용량(used_MB)과 잔여 디스크 용량(free_MB)을 알 수 있다.
출처: fakerdeft
즉, 내가 현재 사용 가능한 용량은 180 - 8.2 = 약 171MB 정도이다.
⭐ 데이터베이스별 용량 확인
이번엔 데이터베이스 별 용량을 확인해야 한다.
SELECT table_schema "database",
ROUND(SUM(data_length+index_length)/1024/1024,1) "size(MB)"
FROM information_schema.TABLES
GROUP BY table_schema
ORDER BY `size(MB)` DESC;
이 쿼리문을 실행하면 데이터베이스 별로 사용중인 용량을 확인할 수 있다.
출처: fakerdeft
프로젝트에 사용되는 데이터는 cfdevDB 내부에 저장되어 있으며, 현재는 약 0.3MB만큼 들어있다.
⭐ 대용량 더미 데이터 넣기 with 프로시저
데이터가 수십 ~ 수백 개 정도로 양이 적다면 힘들긴 해도 직접 insert문으로 넣는 방법도 나쁘지 않다고 생각한다.
그런데 대용량이라 하면 보통 수천 ~ 수만 개 혹은 그 이상의 데이터를 떠올리게 된다.
대체 이 많은 걸 어떻게 넣어야 될까??
우선 나는 기업 검색 API를 테스트할 것이고, 이 API는 company 테이블만 조회한다.
그래서 더미 데이터를 company 테이블에만 넣으면 된다. (개꿀)
10만 개를 우선 넣어서 용량 비교를 해볼 것이고 추가로 몇 개를 더 넣을지 결정할 것이다.
SELECT table_schema "database",
SUM(data_length + index_length)/1024/1024 "size(MB)"
FROM information_schema.TABLES
WHERE table_schema = 'cfdevDB';
출처: fakerdeft
데이터 삽입 전 데이터베이스의 용량이다.
이제 프로시저를 사용해서 10만 개의 데이터를 넣어보자~~
DELIMITER $$
DROP PROCEDURE IF EXISTS insertDummy$$
CREATE PROCEDURE insertDummy()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i <= 100000 DO
INSERT INTO cfdevDB.tbl_company(city, district, name, type, question_count, company_status, created_at)
VALUES('서울특별시', '강남구', concat('가나다', i), '서비스업', 0, 'REGISTRATION', CURRENT_TIMESTAMP);
SET i = i + 1;
END WHILE;
END$$
DELIMITER ;
CALL insertDummy;
프로시저를 실행하고 5분 정도 기다리면
출처: fakerdeft
결과는 기존 15개에 추가로 10만 개가 아주 잘 들어갔다!
출처: fakerdeft
그리고 전체 데이터베이스 사용 용량은 기존 8.2MB 에서 24.7MB 로 증가했고 사용 가능한 용량은 180MB 에서 164MB 로 감소했다.
좀 더 자세히 본다면
출처: fakerdeft
더미 데이터를 삽입한 데이터베이스가 차지하는 용량이 0.3MB 에서 16.8MB 로 16.5MB 정도 증가했다.
즉, 해당 테이블에서 데이터 10만 개 당 16.5MB 정도 공간을 차지한다고 생각을 할 수 있다. (타 테이블에서는 수치가 당연히 다름)
용량이 생각보다 여유가 있는 것 같으니
데이터 50만 개를 넣는 것으로
테스트할 준비를 마무리한다.
🚀 본격적으로 부하 테스트하기
⭐ 계획과 시나리오
부하 테스트는
얼마만큼의 요청을견딜 수있는지테스트해야되는 것이다.
코드나 로컬에서 문제가 발견되지 않더라도
실 운영 상황에서는 예기치 못한 문제로 서비스 중단이 될 수 있다.
병목 현상이나 예기치 못한 문제를 미리 찾아서 예방하는 것이 목적이다.
이를 위해 미리 계획을 수립한다.
✅ 지표
TPS(Transaction Per Second): 초당 요청 처리 수
참고로 TPS 뜻이 누구는 Test Per Second라고 하고 누구는 Transaction Per Second라고 주장해서 공부할 때 너무 헷갈렸다. 그래서 nGrinder 공식 커뮤니티 다 뒤져서 관리자 선생님의 답변을 찾았다. 관리자 피셜이면 누구보다 제일 정확하지 않을까 싶다. 출처: nGrinder
사실 뭐 Test나 Transaction이나 단순한 스크립트에선 의미가 크게 다르다고 생각하진 않는다.
Vuser: 가상 동시 사용자 수
MTT(Mean Test Time): 평균 테스트 시간
MTT랑 MTTFB가 중요하다. 역시 너무나도 헷갈려서 관리자 선생님의 답변을 찾아냈다. 출처: nGrinder
나는 @Test 함수 안에서 다른 로직 없이 단순히 API 호출만 하기 때문에이번 테스트에서는 MTTFB(첫 번째 바이트 평균 도달 시간)를 좀 더 눈여겨보면 될 것 같다.
숙지할 지표를 살펴봤다.
다음은 전제와 테스트 목표를 계획한다.
✅ 전제
테스트하려는 Target 시스템 범위 정하기
부하 테스트 시 저장될 데이터 건수 크기 결정. 서비스 이용자 수, 사용자 행동 패턴, 사용 기간 등을 고려해 계산하기
성능 유지 기간을 설정하기
같이 동작하는 다른 시스템, 제약 사항 등을 파악하기
나는
Target 시스템 범위: EC2 + Spring Boot + RDS
데이터 수: 더미 데이터 50만 개
성능 유지 기간: 30분
이렇게 정했다.
✅ 테스트 종류
1. Smoke 테스트
최소 부하로 맛보기 검증 테스트
2. Load 테스트
평소 트래픽/최대 트래픽일 때 Vuser 계산 후 시나리오 검증 테스트
결과에 따라 개선하면서 테스트 반복
3. Stress 테스트
최대 처리량 한계점을 확인하는 점진적 부하 테스트
테스트 이후 시스템이 자동으로 복구되는 지 확인
✅ 성능 목표
Load 테스트인 경우 다음과 같은 지표로 Vuser 를 구해야 한다.
DAU(일일 활동 사용자 수)
피크 시간 집중률(평소 트래픽/최대 트래픽)
1인 당 1일 평균 요청 수
나는 이런 경험이나 정보가 없으므로
평균 100명을 가정하고 하겠다.
✅ 테스트 목표
1. Smoke 테스트
Vuser: 2
Throughput(처리량): 11.3 ~ 34 이상
Latency(지연 속도): 50 ~ 100ms 이하
2. Load 테스트
Vuser: 100 (나는 평소/최대 트래픽에 대한 지표가 없어서 평균으로 했고 평소/최대 트래픽 나눠서 테스트하는 게 맞다)
Throughput(처리량): 11.3 ~ 34 이상
Latency(지연 속도): 50 ~ 100ms 이하
3. Stress 테스트(이번 글에선 진행하지 않는다.)
Vuser: Ramp-Up을 사용해 점진적 증가
다음과 같이 목표를 세웠다.
그리고 원래는 시나리오를 세워야 하는데
단순히 API 한 개 테스트이므로 생략했다.
스크립트는 미리 작성을 했고
본격적으로 테스트를 진행하였다.
⭐ Smoke 테스트
잘 돌아가는지 검증하기 위한 테스트여서
Vuser는 2, 테스트 기간은 30분을 잡고 진행했다.
결과는 다음과 같다.
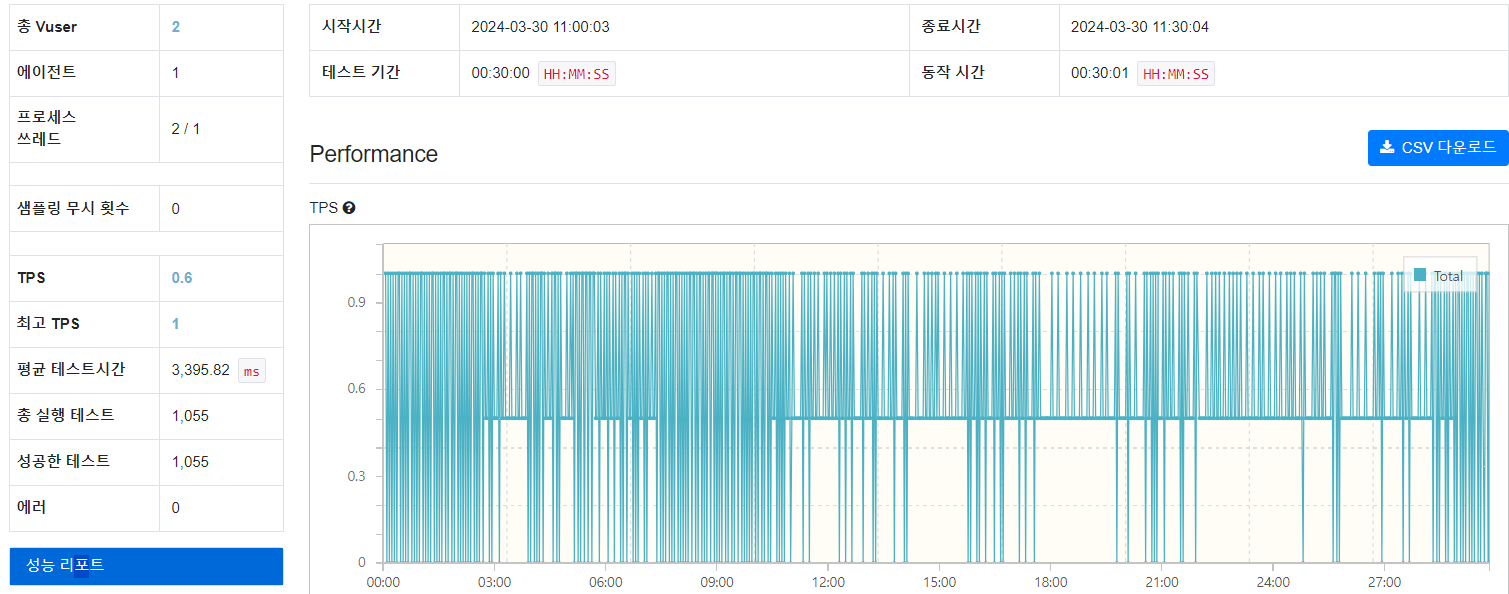
예?출처: fakerdeft
보자마자 속이 터졌던 지표이다...
퍼포먼스 지표를 살펴보면
평균 TPS: 0.6
최대 TPS: 1
MTT: 3395.82 (첫 번째 바이트 평균 도달 시간 = MTTFB 은 여기서 MTT와 거의 일치한다)
Vuser: 2
에러: 0
여기서 평균 TPS가 Throughput이 되고
MTT가 Latency가 된다.
Throughput: 약 0.6
Latency: 약 3400ms
즉, smoke 테스트부터 Throughput, Latency 모두 목표에서 아주 크게 빗나갔다.
Latency 같은 경우 실 서비스에서는 응답 시간을 1초 이하로 줄여야한다.
⭐ Load 테스트
잠깐 자고 일어나보니 예약해 둔 테스트가 끝났었다.
Vuser는 99(100으로 설정하면 자동으로 99가 설정됨), 테스트 기간은 역시 30분을 잡고 진행했다.